








































¿Qué es el Aprendizaje Automático?
El Aprendizaje Automático es una parte de las ciencias de la computación, muy ligada a la Inteligencia Artificial (AI), que a partir de la aplicación de algoritmos pueden llegar a aprender, establecer patrones sobre los datos, y realizar predicciones sobre los mismos. El siguiente vídeo explica de una forma muy gráfica “Qué es el Aprendizaje Automático”:
[av_video src=’https://www.youtube.com/watch?v=bHvf7Tagt18′ format=’16-9′ width=’16’ height=’9′]
¿Cuáles son sus aplicaciones prácticas?
Esta definición un tanto futurista y que a priori parece tan alejada de nuestra rutina diaria, tiene aplicaciones tan actuales como:
- Detección de spam en mensajes de correo electrónico.
- Detección de fraudes con tarjetas de crédito.
- Reconocimiento de voz.
- Detección de rostros para identificación de personas.
- Recomendaciones de productos en webs de venta online.
- Diagnósticos médicos para identificación de enfermedades basados en sus síntomas.
- Segmentación de clientes para determinar si un posible cliente que se encuentra en una determinada fase en el proceso de ventas llegará a comprarnos nuestro producto o servicio.
- Predicción de venta de viviendas.
- En ciberseguridad, para detección de ataques y mitigación de sus posibles efectos
Las grandes compañías ya lo están usando para mejorar y potenciar sus servicios:
- Google está desarrollando un servicio llamado “Smart Reply” que se integrará en GMail y que nos permitirá responder de forma automática a correos de entrada. Pero es que ya hay aplicaciones integradas en nuestros dispositivos, como Google Now¸ que ya está poniendo en práctica estas tecnologías desde hace tiempo:
- Microsoft integrará los servicios de “Azure Machine Learning” en su CRM Dynamics 2016 para ayudar a las empresas a obtener una más rápida y más efectiva experiencia a los clientes, suministrando un sistema de gestión del conocimiento que permita a las empresas registrar y acceder a información en la resolución de problemas. El sistema irá aprendiendo de forma continua conforme vaya creciendo la interacción cliente-empleado.
- Facebook a través de su equipo de AI llamado FAIR (“Facebook AI Research”) está trabajando en algoritmos que permitan mostrar información a los usuarios de forma mucho más selectiva, y ello incluye por supuesto en el filtrado de imágenes y fotos.
Y los ejemplos y aplicaciones prácticas son cada día más numerosos y afectando a todas y cada una de las áreas de nuestra vida cotidiana.
Un breve repaso sobre los Algoritmos de Aprendizaje Automático
Sin pretender entrar en cuestiones técnicas, fórmulas matemáticas, estadísticas, etc., sí que me gustaría mencionar de forma muy breve los diferentes tipos de algoritmos utilizados en problemas de Aprendizaje Automático.
La primera clasificación de los algoritmos atiende a la forma en qué los datos son presentados al sistema de aprendizaje, y podemos tener:
- Aprendizaje Supervisado. Se presentan los datos de entrada perfectamente definidos y etiquetados y se conoce cuáles son las salidas que deseamos obtener. Por ejemplo, dado un conjunto de imágenes de animales etiquetadas según su raza, queremos predecir a qué raza de animal pertenece una nueva imagen suministrada al sistema.
- Aprendizaje No Supervisado. Los datos de entrada no están definidos, y se deja al algoritmo que encuentre la estructura y patrones de comportamiento en ellos. Siguiendo con el ejemplo anterior, podemos suministrar un conjunto de imágenes de animales sin etiquetar al sistema, con el objetivo de establecer agrupaciones en función de patrones de similitud entre ellas.
La otra clasificación atiende a la función del algoritmo y la salida qué esperamos del mismo. En este sentido podemos tener principalmente los siguientes:
- Regresión. Trata de modelar las relaciones entre variables mediante múltiples iteraciones que se van refinando en función de una medida de error.
Por ejemplo, se podría aplicar para predecir el precio de una vivienda teniendo en cuenta múltiples factores, como es el caso de la superficie, número de habitaciones, ciudad, barrio, etc. - Clasificación. Se utiliza para estimar valores discretos (0/1, Verdad/Falso, Sí/No) en función de un conjunto de variables independientes. Se conoce también como “Regresión Logística”.
Ejemplo de aplicación sería la clasificación de un e-mail como spam, en función del texto, asunto, emisor, etc. - Agrupamiento (“Clustering”). Trata de encontrar patrones en la estructura de los datos para organizarlos de tal forma que permita agrupaciones por las mayores similitudes posibles.
Se podría aplicar, por ejemplo, para clasificar cualquier tipo de artículo por temas según su contenido: deportes, ciencias, literatura, etc. - Recomendación. Busca predecir el grado de preferencia que un usuario proporciona a cualquier elemento. Es el caso de la recomendación de productos para la venta online, en función de compras anteriores, preferencias de artículos anteriormente visitados, histórico de compras de otros clientes, e incluso de características personales, como el sexo, la edad, etc.
- Aprendizaje profundo (“Deep Learning”). Construyen mayores y más complejas redes neuronales para resolución de casos en los cuales tenemos grandes volúmenes de datos que pueden no estar etiquetados, o estarlo parcialmente. Se utiliza por ejemplo en temas relacionados con visión por computador, para cuestiones cómo la clasificación de una imagen atendiendo a ciertas facetas que la puedan identificar.
Una infografía muy visual del funcionamiento de estos algoritmos es A Visual Introduction to Machine Learning y para conocer otras clasificaciones y más en profundidad cada uno de ellos, os invito a leer A Tour of Machine Learning Algorithms.
¿Cómo podemos usarlo sin ser expertos?
Estamos viviendo una verdadera explosión con gran variedad de ofertas relacionadas con el Aprendizaje Automático. Hace unos pocos años era un campo reservado a centros de investigación creadores y propietarios de potentes algoritmos inaccesibles a quién no pudiera ser experto en la materia.
Por otra parte, han surgido proyectos creados y mantenidos por la comunidad que ponen a disposición del público en general aplicaciones y librerías que permiten a cualquiera menos profano en la materia el acceso en sus propias aplicaciones de este tipo de algoritmos. En este enlace se puede echar un vistazo a alguno de estos proyectos.
Además, debido a los propios requisitos, bastante exigentes de la infraestructura sobre la que debe correr este tipo de aplicaciones, las grandes empresas de alojamiento en la nube, como es el caso de Microsoft con Azure Machine Learning y Amazon con Machine Learning, han dispuesto de servicios para la ejecución y utilización de en nuestras aplicaciones del Aprendizaje Automático:
Y por último, para completar la oferta, ya están todas las grandes empresas proporcionando a cualquier usuario la posibilidad de acceder a proyectos abiertos, donde se proporcionan algoritmos, documentación y ejemplos para el acceso a los algoritmos:
- Microsoft con Oxford.
- Google con TensorFlow.
- Facebook con FAIR.
No se pueden utilizar todos estos algoritmos sin ningún tipo de formación, pero sin ser un experto en Matemáticas o Estadísticas, ya se puede acceder a formación online que nos proporcionará los conocimientos básicos necesarios para comenzar a trabajar con estos algoritmos, y abrirnos la puerta al Aprendizaje Automático.
Conclusión, el futuro ya está aquí
Podemos dar un vistazo al “Estado del Arte” en Aprendizaje Automático, con los sectores y empresas ya utilizando estas tecnologías en este análisis de Shivon Zilis.
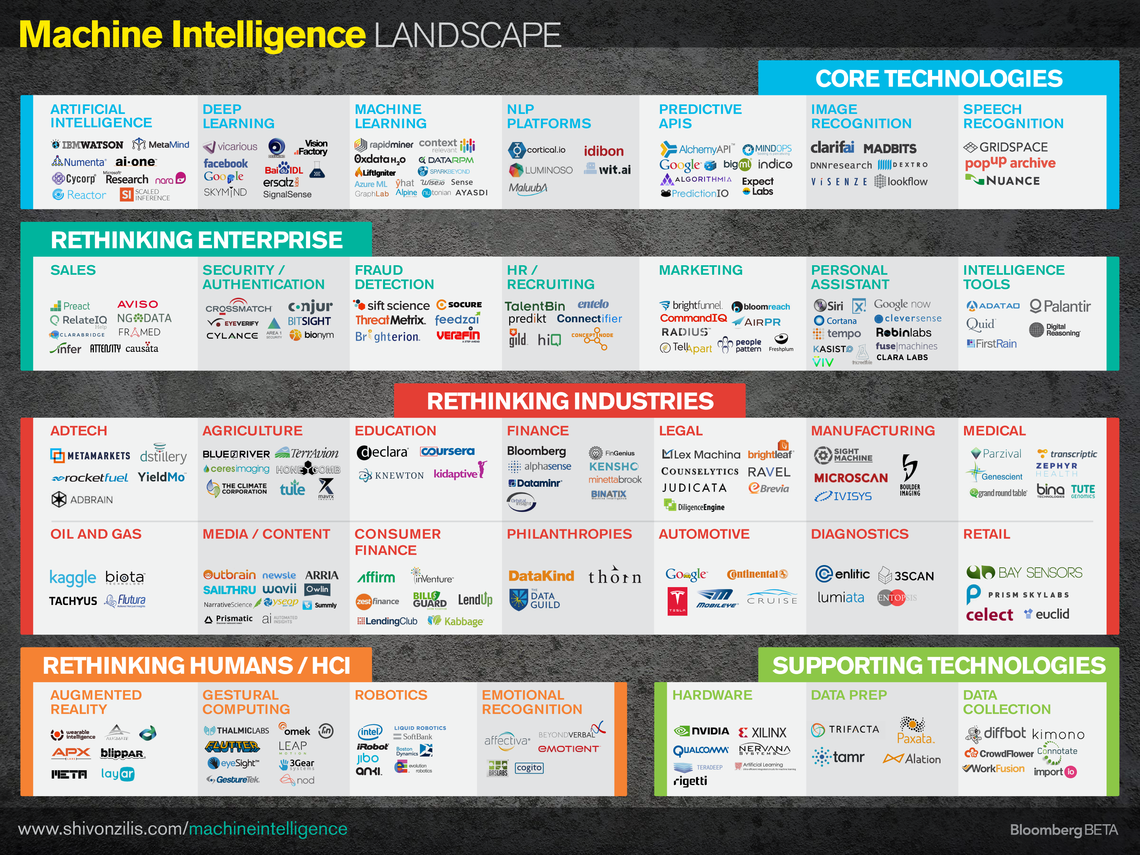
Como se ha comentado, ya estamos usando aunque pasen desapercibidos estos algoritmos en muchas de las facetas de nuestra vida diaria, en aplicaciones totalmente integradas con nuestros dispositivos, pero su uso va a ir mucho más allá, y los investigadores siguen trabajando en algoritmos cada vez más perfectos.
Con el acceso cada vez más fácil a estas tecnologías por parte de cualquiera, las ventajas competitivas son tan importantes que ninguna empresa tecnológica podrá despreciar su utilización. Y finalizo con una cita de Pedro Domingos, uno de los grandes científicos del Aprendizaje Automático:
“Los mejores algoritmos determinan quién gana y pierde en una economía digital que se alimenta de dirigir al consumidor hacia un oportuno click”
Director de Desarrollo y Diseño I+D en Clavei. Posee certificación como Project Management Professional

muy interesante